





厳密な定義よりも内容のイメージを受け取ってもらえたら嬉しいです。
じっくり1回読むより、ザーッと2回見た方がいいかもしれません(時間かけるなら2回目がいいです)。
データモデル
・構造
・データ操作
・一貫性制約
の3つの構成要素からなるのものをデータモデルと呼びます。
データモデルは何種類もあるので、主要な2つを紹介します。
関係モデル
最もよく使われるモデル。
表でデータをまとめる。
生徒
| 学生番号 | 名前 | 部活 |
| 1 | 多摩 | 生物 |
| 2 | 石川 | 海洋学 |
| 3 | 八景島 | シーパラダイス |
ERモデル(実態関連モデル)
Entity-Relationship modelは、「実態」と「関連」に分けて考える。
当然数学のようにギチギチに明確な分け方ではなく、人間の感覚で分ける。
「生徒」「教師」などは実態に分類し、
「授業」は「生徒」と「教師」の間の関連と考えられる。
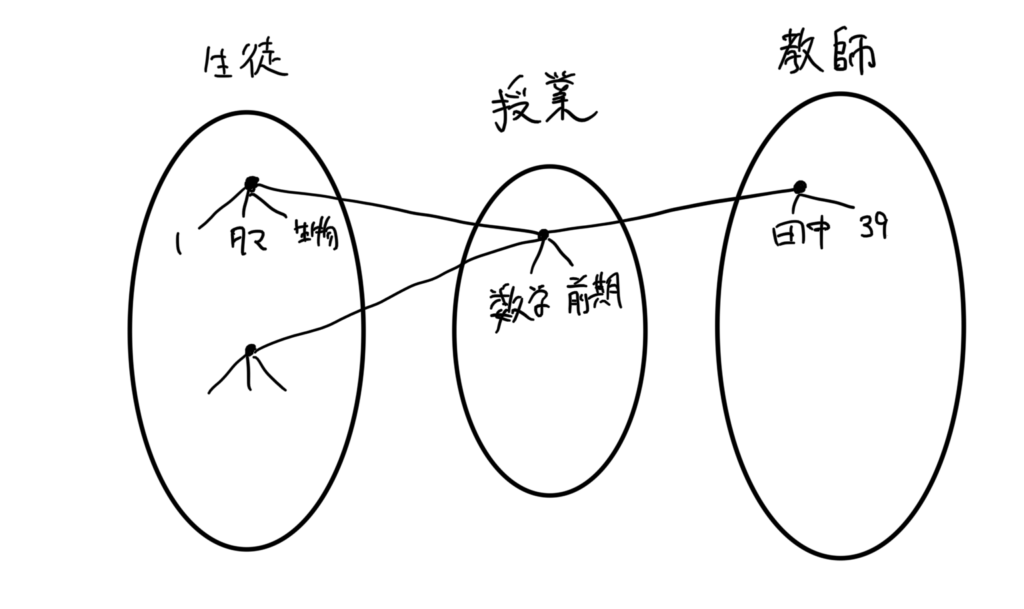
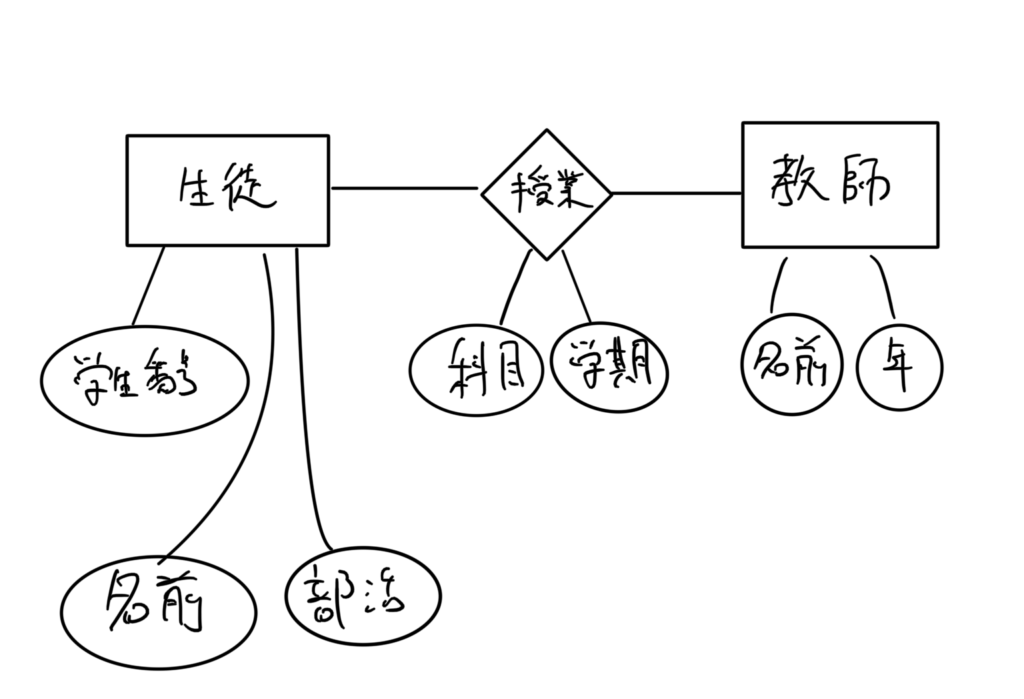
データベースのスキーマ(枠組み)が
生徒(学生番号, 名前, 部活)
授業(科目, 学期)
教師(名前,年齢)
だとすると、ER図(実態関連図)にすると↓になります。
また、データベースを見ていく際に必須の概念としてインスタンスというものがあります。
スキーマ(枠組み)+ インスタンス = データベース
ってイメージです。スキーマは容器で、インスタンスは中身。
データ独立性
結論を言ってみると、
内部スキーマ(物理的な記憶装置とか)変更→DBMSが中継してくれるので→概念スキーマ(インスタンスの枠組み)はそのまま その概念スキーマを変更→ビューが中継してくれるので→SQLはそのまま
ですが、これだけでは「?」なので、少し掘り下げていきます。
論理的データ独立性

実は↑で解説したのが論理的データ独立性のことでした。読んだ前提で書いてみます。すいません。
ビュー(外部スキーマ)と概念スキーマ(生徒とか教師を定義する枠組み)を分けることによって、概念スキーマを変更しても、SQLの命令に影響ないのでした。
1文でまとめるなら、
概念スキーマ変更→ビューが中継してくれるので→SQLはそのまま
物理的データ独立性
そもそもデータは物理的な記憶装置に格納されています。

なので物理的特性を考慮したファイル編成方法をしたい。
データを格納する記憶装置+ファイル編成方法=内部スキーマ
ってイメージです。熱帯魚とかのの水槽セットがスキーマなら、水槽+水の浄化装置とか=水槽セット って感じでしょうか。
さて、物理的データ独立性とは、概念スキーマ(生徒とか教師を定義する枠組み)と、内部スキーマ(記憶装置とファイル編成方法)が独立しているということです。
データベース管理システム(Database Management Systems (DBMS))が概念スキーマ(生徒とか教師を定義する枠組み)とファイル(内部スキーマ)の対応管理を任せることによって、独立性が実現できます。
概念スキーマ(生徒とか教師を定義する枠組み)を変更したとしても、内部スキーマ(記憶装置とファイル編成方法)を変更する必要がないのです。
生徒が増えすぎて古い生徒ファイルは別の記憶装置(内部スキーマ)変更したいときに、独立性がないと、概念スキーマ(生徒とか教師を定義する枠組み)にも影響が出てしまいます。
1文でまとめるなら、
内部スキーマ変更→DBMSが中継してくれるので→概念スキーマはそのまま
関係データベース
データを表で管理しようっていう自然な考え方による方法。
さっきの関係モデルをもとにデータベースを作る。
例えば、学生のデータを管理したい場合
(学生(学生番号, 名前, 年齢, Σ(学生) ) Σ(学生)は次のような一貫性制約を持つ。 σ1:属性「学生番号」に現れる値は重複しない σ2:属性「学生番号」の値として許されるのはString(文字列というデータ型)のみ σ3:属性「名前」の値として許されるのはStringのみ σ4:属性「年齢」の値として許されるのは整数値のみ
みたいな感じです。
「学生番号」「名前」「年齢」(関係の属性)+「学生」(関係スキーマ名)+一貫性制約=関係スキーマ
となっています。
キー
定義は
・(一意性)とある属性の値分かれば、一意にインスタンスが決まる
・(極小性)「キー」の真部分集合では一意に決まらない
という感じです。
学生(学生番号, マイナンバー, 名前, 部活, 年齢)
という関係スキーマ(インスタンスの枠組み)なら、学生番号orマイナンバーがわかれば、学生(インスタンス)が一意に特定できる。
このように、「これがわかれば、一意に決まる」という属性を「候補キー」と呼びます。(まだ、極小性がないので「キー」ではないです)
上で言うと、学生番号は候補キーであり、マイナンバーも候補キーです。
繰り返しになりますが、学生番号とマイナンバーはどっちか1つだけわかれば学生が誰なのか決まるので、{学生番号, マイナンバー}という要素が2つある集合はキーになれません。
そして、候補キーの中から、人間の感覚的にこれをメインにすべきだと思ったものを「主キー」として選びます。今回なら「学生番号」でしょう。学校のデータベースだし。
候補キーの中から主キーを選びました。選ばれなかったものは、「代替キー」と呼びます。「主キーの代わりになれるよ(インスタンスを特定できるよ)」ってことですね。
関係内参照制約(場合によっては追加しないといけない一貫性制約)
社員(社員id, 上司id, 名前, 年齢)
を考えてみます。
上司もその会社の社員なので、上司idはその上司の社員idのはずですね。
つまり、上司idは社員idのどれかと一致しなければならない。
このときは、↓のように表します。
社員.上司id ⊆ 社員.社員id
コメント